Kimi-K2.5: Visual Agentic Intelligence
Kimi-K2.5 is Moonshot AI's most powerful model — a native multimodal agentic model with 1 trillion parameters (32B activated), trained on 15 trillion mixed visual and text tokens, with a 256K context window.
Key highlights:
- AIME 2025: 96.1%
- MMMU-Pro: 78.5% — 🌟 I mainly contributed to this!
- SWE-Bench Verified: 76.8%
Features include native multimodality, an agent swarm architecture (up to 100 parallel sub-agents), and state-of-the-art visual code generation from UI designs.
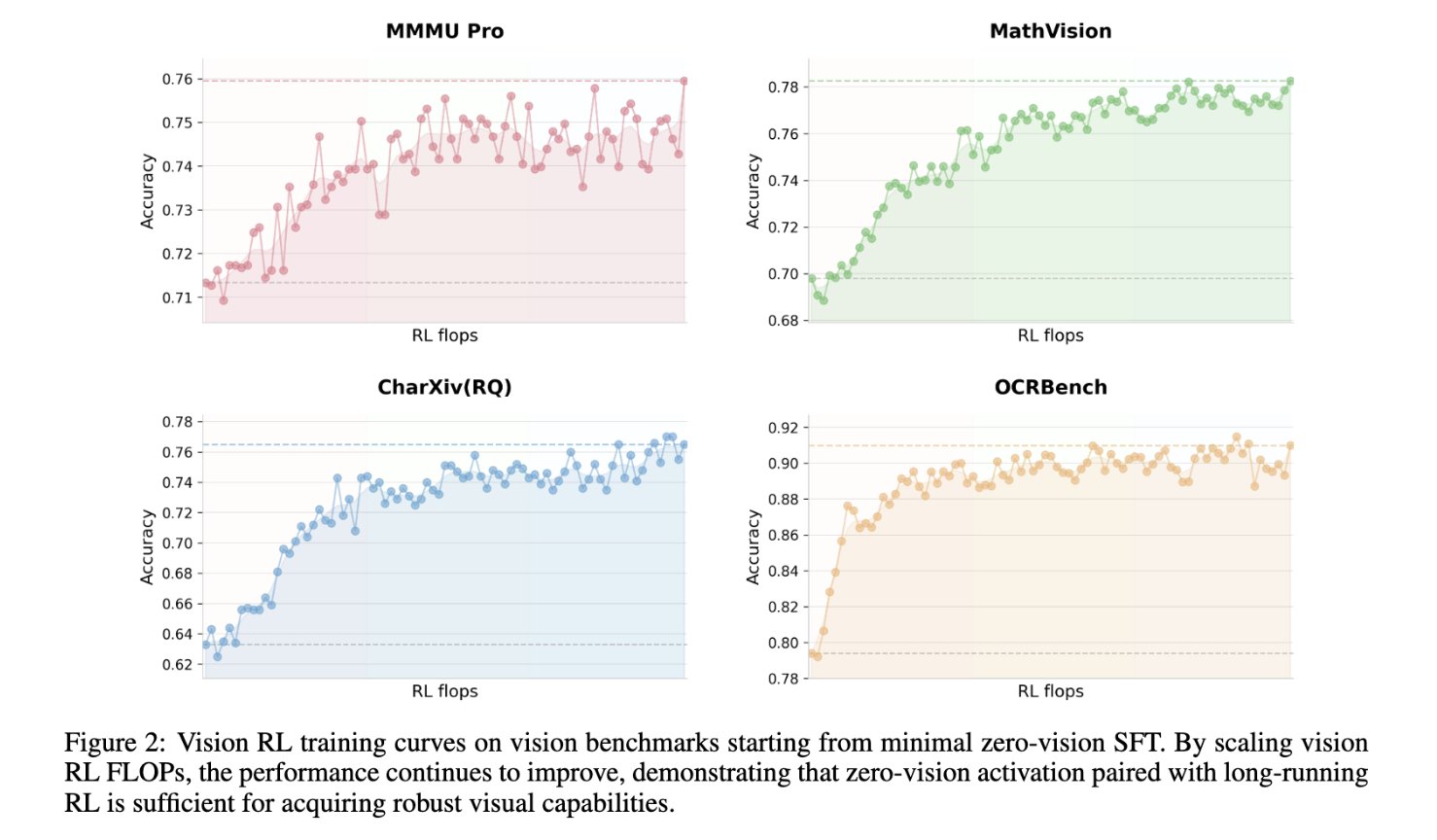
I work on the Native Multimodal RL effort, documented in K2.5 Report Chapter 2.2:
- 🔹 ZeroVision ColdStart → Vision-Centric RL: Starting from a Zero Vision SFT model (text-only thinking SFT, no vision SFT) to preserve the base model's strong Pass@N, then applying pure Vision RL
- 🔹 Vision Reasoning & Knowledge & TIR RL
- 🔹 Chart Understanding and Chart-to-Code
Zero Vision SFT -> Pure Vision RL — 心路历程
起手做thinking的时候,高质量的Vision Thinking Data是非常稀缺的,但因为K2-Thinking,我们有很多高质量的text thinking data可以做sft,加上K2.5的Base模型的vision能力非常强,Zero Vision SFT版本的模型就自然地被haoning快速地拿出来了。这个模型直接用来测分并不强,可以看到Fig2的起点是挺烂的,但因为Base模型强,且没有Vision SFT的影响(质量不够的情况下就会影响),他的Pass@N理所应当地保留下来了,这是一个非常适合去做Vision RL的起点!
震惊: 最初发现这个现象是在InfoVQA上,这个bench有两个特点:刚需高分辨率识图 以及 对输出格式要求极其严格,Zero Vision SFT的模型起点只有50-60分,但在RL里做10次权重更新就可以到几乎SOTA的分数...这个1T的模型在10次更新中就完成了修格式、修感知、pass@k -> pass@1等等,小小的我产生了大大的震惊,于是梭哈了LongRun,就跑出了上述Fig2这样非常优美的曲线(这还是eval,train只会更优美...)
震惊²: 值得一提的是,这个figure只是我们观测的部分,让我震惊程度再上一个level的是,在其他完全没进job观测,只在开始和结束测一些的Vision Benchmark里,效果也非常非常好!
震惊³: 有一次下去拿外卖遇到了zijia,他说这个模型直接就可以roll出质量不错的vision toolcall轨迹,可以说这个完全是Text SFT + Vision RL的大泛化!其他没观测的benchmark泛化还算可以想象,toolcall这个已经在我的认知范围外了orz
震惊⁴: 来自haoning的神仙sense,我们发现这次纯Vision的RL能涨text的knowledge,MMLU-Pro、GPQA都有涨!就像Text SFT的Pattern可以通过Vision RL上来达到泛化又不分脑地迁移到Vision Pattern,Vision RL后低幻觉 + 高信息量的Pattern也会泛化到Text里,这应该是Text Knowledge上升的原因,本质左脚踩右脚飞升!
在做到这些之后,就有了非常高质量的vision thinking data了,后续RFT + RL的loop就按部就班做下去了,现在是完全坚信longrun!内科没问题且不reward hacking,就一直跑下去吧!!!有问题再出手,哪怕是安慰剂...
BTW,这次LongRun中间我对K2.5的打扰是非常少的...我只需要在内科出问题的时候调个参push or pull他一把,在似乎有点hack迹象的时候把judge / filter魔改一下,就没我事了,让他跑着就好,这就是Trillion级别模型的魅力吗...靠,显得我好没用...
写在最后
作为一个刚进入职场的校招小卡拉米,在过去一段时间重新体会了"累并快乐着",好像是global-local,整体是累着的,但只需中间某些时刻的快乐就能一定程度冲淡了整体的累。熬过的夜在最后K2.5端上来的时候都只剩下兴奋和朋友圈里迫不及待地"Proud of the journey"!BTW,观点仅供参考orz